Mitchell Hashimoto
Grapheme Clusters and Terminal Emulators
Copy and paste "🧑🌾" in your terminal emulator. How many cells forward did your cursor move? Depending on your terminal emulator, it may have moved 2, 4, 5, or 6 cells1. Yikes. This blog post describes why this happens and how terminal emulator and program authors can achieve consistent spacing for all characters.
Character Grids, Historically
Terminals operate on a grid of fixed size cells. This is fundamental to how terminal emulators operate because many control sequences programs can send to the terminal operate on cells.
For example, there is a control sequence to move the cursor left
CSI n D, right CSI n C, up CSI n A, or down CSI n B. The
"n" in each of these is the number of cells to move. There is
a sequence to request the cursor position CSI 6 n. The terminal
responds to the program in the form CSI y ; x R where both "y"
and "x" are cell coordinates.
Traditionally, terminals simply read an input byte stream and mapped each individual byte to a cell in the grid. For example, the stream "1234" is 4 bytes, and programmers can very easily read a byte at a time and place it into the next cell, move the cursor right one, repeat.
Eventually, "wide characters" came along. Common wide characters are
Asian characters such as 橋 or Emoji such as 😃. A function
wcwidth
was added to libc to return the width of a wide character in cells.
Wide characters were given a width of "2" (usually). Therefore, if
you type 橋 in a terminal emulator, the character will take up two
grid cells and your cursor should jump forward by two cells.
And this is how most terminal emulators and terminal programs (shells,
TUIs, etc.) are implemented today: they process input characters via
wcwidth and move the cursor accordingly. And for a short period of time,
this worked completely fine. But today, this is no longer adequate and
results in many errors.
Grapheme Clustering
It turns out that a single 32-bit value is not adequate to represent every user-perceived character in the world. A "user-perceived character" is how the Unicode Standard defines a grapheme.
Let's consider the emoji "🧑🌾". The emoji should look something like this in case your computer doesn't support it. I think every human would agree this is a single "user-perceived character" or grapheme. The Unicode Standard itself defines this as a single grapheme so regardless of your personal opinion, international standards say this is one grapheme.
For computers, its not so obvious. "🧑🌾" is three codepoints (U+1F9D1 🧑, U+200D, and U+1F33E 🌾), three 32-bit values when UTF-32 encoded, or 11 bytes2 when UTF-8 encoded.
If we only consider the 32-bit values and send each one individually
to wcwidth as we historically have done, we'll get the results of
"2", then "0", then "2", respectively for each codepoint. Therefore, the
cursor moves forward by 4 cells. This is why with most terminals (at the
time of writing this), you'll see your cursor move forward by 4 cells
What's with the zero-width character? The codepoint U+200D is known
as a Zero-Width Joiner
(ZWJ) and has a standards-defined width of zero. The ZWJ tells text
processing systems to treat the codepoints around it as joined into
a single character. That's why you can type both "🧑🌾" and "🧑🌾";
the only difference between these two quoted values is the farmer on the
left has a zero-width joiner between the two emoji.
Enter grapheme clustering. Grapheme clustering is the process of determing a single grapheme from a stream of codepoints. Grapheme clustering is the process that lets a program see three 32-bit values as a single user-perceived character. The algorithm for grapheme clustering is defined in UAX #29, "Unicode Text Segmentation". I won't go into detail how the algorithm works, just grab any modern Unicode library for your programming language and it should be able to perform grapheme clustering.
A particular challenge with grapheme clustering is that it is stateful. You must have access to the previous codepoint, the current codepoint, and an integer state value to robustly determine the break points for graphemes. Therefore, it isn't super easy (but its not hard) to drop into an existing program.
With grapheme clustering, a terminal would see "🧑🌾" as a single wide-character grapheme and move the cursor forward only two cells instead of four.
This isn't just for emoji. I'm using emoji as an example but grapheme clustering is also extremely important for correctly handling the languages of the world. For example, Arabic characters are often made up of multiple codepoints.
Aside: font shaping. Grapheme clustering only solves the problem of determining grapheme boundaries in a stream of codepoints. It does not solve the problem of rendering a stream of codepoints. For that, you need a font shaper such as Harfbuzz. Harfbuzz sees a stream of codepoints, detects the graphemes, and is able to then map those graphemes to individual glyphs in a font.
This blog post won't cover font shaping, but if you paste "🧑🌾" in a terminal and see two emoji instead of one, its either due to the terminal stripping the zero-width joiner or more likely because the terminal doesn't support font shaping.
Grapheme Clustering in Terminals
Most terminals today do not support grapheme clustering. A major reason is because advanced terminal applications such as shells and text editors often need to constantly know exactly where the cursor is and remain in sync with the terminal grid state.
Because historically terminals used wcwidth, shells, editors, and other TUI
apps also use wcwidth, and continue to do so today. Even though it produces
the wrong values for multi-codepoint graphemes, at least the wrong values
are often consistently wrong across terminal emulators.
When I first implemented text processing for my terminal,
I implemented full grapheme cluster support because I assumed that would be
a good thing. However, I was immediately disappointed to find that when
I did proper grapheme clustering, fish shell
would redraw my prompt in the wrong place when I moved my cursor. 😞 My
shell assumed my terminal used wcwidth, and my terminal assumed programs
didn't care. We both were wrong, so I disabled grapheme clustering...
Enter mode 2027. Mode 2027 is a proposal for grapheme support in terminals. This proposal is from the author of the Contour terminal. The idea is that a program running in a terminal can notify the terminal that it wishes to operate with full support for grapheme clustering, and this feature can be turned on and off. The running program can also query the terminal to see if it supports this feature.
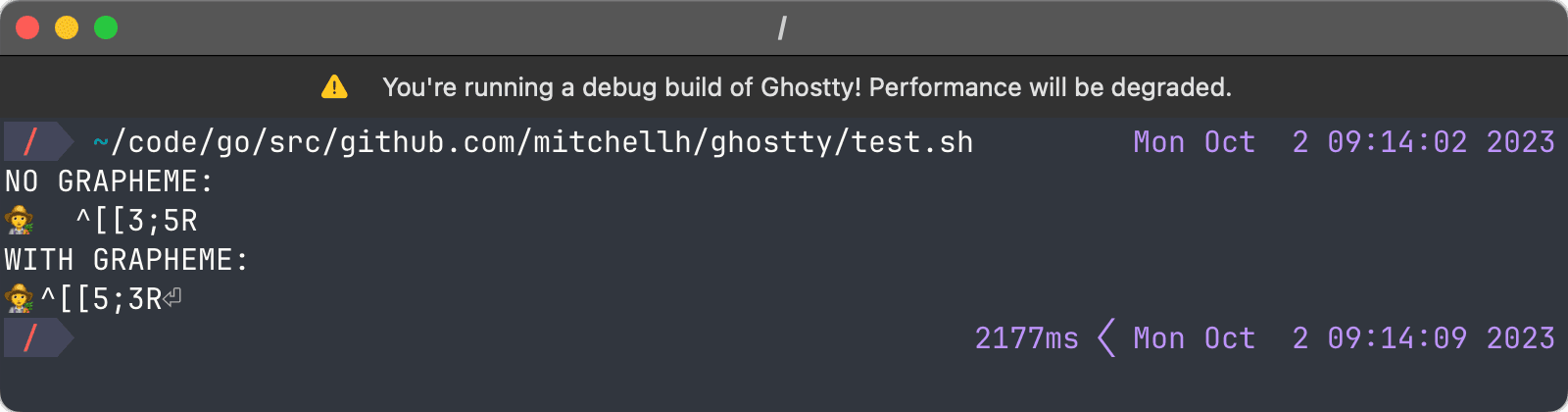
I recently implemented support for mode 2027 in my terminal and you can see it working below. With mode 2027 off, the cursor moves to column 5 after the farmer emoji (width of 4). With mode 2027 on, the cursor moves to column 3 (width of 2).
Terminal Comparison
The table below shows the reported width of "🧑🌾" by various terminals. For each terminal, I used the latest version I could find as of October 2, 2023. I put my own terminal first in the list but otherwise listed them alphabetically.
| Terminal | Width | Mode 2027 | Notes |
|---|---|---|---|
| Ghostty | 2 | ✅ | Falls back to wcwidth if mode 2027 is disabled |
| Alacritty | 4 | ❌ | Doesn't support shaping, displays as two separate emoji |
| Contour | 2 | ✅ | Invented Mode 2027, always performs grapheme clustering |
| Foot | 2 | ✅ | Falls back to wcwidth if mode 2027 is disabled |
| Gnome | 4 | ❌ | Doesn't support shaping, displays as two separate emoji |
| iTerm | 2 | ❌ | Always performs grapheme clustering |
| Kitty | 4 | ❌ | |
| Tmux | 4 | ❌ | Particularly fun when this doesn't match the terminal emulator |
| Terminal.app | 6 | ❌ | 🤡 Living in its own cursed little world |
| Warp | 4 | ❌ | Doesn't support shaping, displays as two separate emoji |
| Wezterm | 2 | ✅ | Always performs grapheme clustering |
| Windows Terminal | 5 | ❌ | 🧐 Considers ZWJ one cell, displays as two separate emoji |
| Xfce | 4 | ❌ | Doesn't support shaping, displays as two separate emoji |
| xterm | 4 | ❌ | Doesn't support shaping, displays as two separate emoji |
Mode 2027 support is still rare and relatively unsupported. Its interesting to see however the variance in reported width across all terminals. "2" and "4" are both understandable values. The terminals reporting "5" and "6" are living a weird reality.
One special challenge is terminal multiplexers such as tmux or zellij.
Notice above that tmux uses wcwidth and thus moves the cursor forward by
four. But tmux itself lives in a terminal emulator which also sees the value
when printed. If tmux and the terminal don't match, the cursors become out
of sync and the resulting bugs can be comical3.
What Can Program Authors Do Today?
If you're the author of a program that runs in a terminal (text editor, CLI, TUI, etc.), there are things you can do today to handle grapheme clusters more appropriately.
One, you can just not care. If your program doesn't need to keep track of where the cursor is, doesn't need to manually line-break, etc. then you can simply not care and let the terminal do whatever it does.
Two, you can and should query for mode 2027 support and try to use mode 2027
if it works. You can query for mode 2027 support using the standard sequence
DECRQM (request mode): CSI ? 2027 $ p.
Three, you can query the cursor position after outputing a series of text
using CSI 6 n. The terminal will then report where the cursor is and you
can use this to calculate the width of your text.
What you should not do is assume wcwidth behavior or grapheme
clustering behavior. You can see from the table in the previous section
that either assumption would be wrong across multiple terminal emulators,
even if you only consider the popular or mainstream ones.
Hopefully in the future more terminals and terminal programs will support mode 2027 and proper grapheme clustering. As noted earlier, this doesn't just impact "cute" features such as emoji but also affects various world languages such as Arabic.
If you're not a terminal or terminal program author, hopefully you found this blog post insightful. Implementing a terminal emulator was certainly eye-opening for me to see the complexities in text processing and the burden of legacy behaviors.
I also want to give a quick shout out to Christian Parpart for proposing mode 2027. Christian is the first person I saw very publicly talk about the issues with grapheme clusters and terminals and also decided to try to do somthing about it. Thank you!